본 글은 stanford university에서 제공하는 cs231n 2017ver 강의 영상을 보고 정리, 요약한 것입니다.
cs231n 2017년 강의영상 : https://www.youtube.com/playlist?list=PL3FW7Lu3i5JvHM8ljYj-zLfQRF3EO8sYv
Lecture Collection | Convolutional Neural Networks for Visual Recognition (Spring 2017)
Computer Vision has become ubiquitous in our society, with applications in search, image understanding, apps, mapping, medicine, drones, and self-driving car...
www.youtube.com
Image Classification은 Computer Vision에서 가장 중요한 과제이다. Image Classification은 시스템이 이미지를 입력 받아야하고 이 시스템은 입력받은 이미지를 자동차, 사람, 고양이, 핸드폰 등의 카테고리 중 어느 집합에 속하는 지 고르는 것이다. 이것이 우리한테는 매우 쉬운 문제이지만 기계인 컴퓨터에게는 매우 어려운 문제이다. 컴퓨터가 보는 이미지는 아래 그림처럼 단지 숫자 배열로 보이고 이를 인식해야하는 것이다.

위 사진에서 숫자 배열은 각 픽셀을 나타내고 이는 세 개의 숫자로 표현된다. 이 세 개의 숫자는 각각 R, G, B를 뜻한다. 이런 숫자 배열을 보고 컴퓨터는 이를 고양이라고 인식해야한다. 고양이라는 이름은 사람인 우리가 붙인 것일 뿐 컴퓨터가 보는 것과는 큰 차이가 있다. 이를 Semantic Gap(의미상의 차이)라고 생각하면 될 것 같다.
이 문제는 해결하기 어려운데 아래와 같은 다양한 문제가 있기 때문이다.

조명문제는 위치에 따라 고양이가 밝게 보이는 고양이가 될 수도 어둡게 보이는 고양이가 될 수도 그림자가 있는 고양이가 될 수도 있고 이에 따라 픽셀값도 변화될 수 있다는 문제이다.

고양이는 변형이 가장 쉬운 동물 중 하나일 정도로 다양한 자세가 있는데 이 모두 같은 고양이로 인식해야한다는 것이다.

정확한 한글 뜻을 모르겠지만 폐색이라고 번역되는 것 같고, 객체 전체가 보이지 않는 것, 맨 오른쪽 그림처럼 꼬리만 보이더라도 고양이로 인식할 수 있어야한다는 것이다. 즉, 매우 적은 픽셀만 보고도 알 수 있어야한다.
이건 좀..? 이런 뜻이 맞는 지 정확히 모르겠다. 사람은 볼 수 있다 이런 식으로 설명했던 거 같은데

배경과 유사할 때 픽셀 단위로는 차이가 많이 안 나 문제로 본 것 같다.

분류해야할 클래스는 범위가 넓다. 예시로 고양이라는 카테고리에 있더라도 모양, 크기, 색상, 나이 등이 다양해 다를 수 있다는 것이다.
좋은 이미지 분류기는 이런 다양한 문제들에 대해 변함없이 분류를 수행할 수 있어야한다.
데이터 중심 접근 방법

데이터 중심 접근 방법의 순서는 다음과 같다. 엄청 많은 데이터를 수집하자는 것이다. google image search나 비슷한 도구를 활용해 데이터를 수집한다. 다음으로 수집한 데이터로 기계학습 분류기를 학습시킨다. 이후 새로운 이미지로 평가를 하는 방식이다.
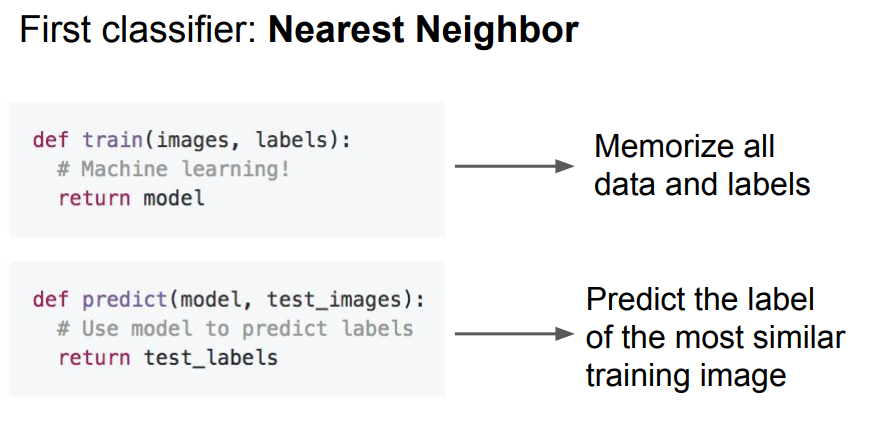
Nearest Neighbor은 가장 단순한 분류기이다. 꽤나 멍청 해당 모델은 학습 단계에서 모든 학습 데이터를 학습해 모델을 만든다. 예측 단계에서는 새로운 이미지가 들어왔을 때 기존 학습 데이터와 비교해 가장 유사한 이미지로 레이블을 예측한다.
그렇다면 어떤 방식으로 이미지를 비교할까?
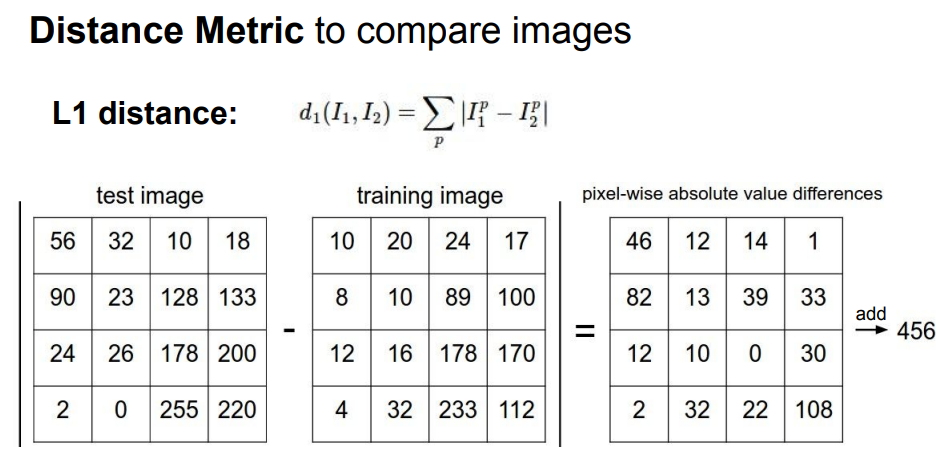
처음 제시된 방법은 L1 distance 또는 Manhattan distance라고 불리는 방법을 사용한다. 간단한 방법으로 이미지의 개별 픽셀을 비교하는 방법이다. 수식으로 표현하면 위 사진에 보이는 것과 같다. 말로 풀어서 설명하면 예측 이미지와 기존 이미지의 각 자리마다 픽셀을 서로 빼고 절댓값을 취해 나온 값을 모두 더하는 것이다.
python 코드에 대한 설명은 빼도록 하겠다. 강의 참고!

N개의 이미지가 있을 때 학습이나 예측하는데 걸리는 시간이 얼마나 되냐는 것이다.
학습시간의 경우 데이터 기억만 하면 되서 상수시간 O(1)이지만 예측시간은 N개의 학습 데이터를 모두 비교해야해 O(N)으로 매우 느리다. 우리가 만들고자 하는 모델은 학습시간은 느려도 되지만 예측은 빠른 분류기를 원하는데 해당 모델은 반대다. 학습시간이야 데이터 센터나 이런 곳에서 학습을 해도 되고, 성능을 위해서 어느정도 느려도 된다는 설명이다. 다만, 예측시간은 해당 모델이 휴대폰이나 저전력 디바이스와 같은 다양한 환경에서 동작하길 원하기 때문에 빨라야한다. 예시로 CNN을 들었다. CNN은 학습시간은 오래 걸릴지라도 예측시간은 짧다.

NN 분류기를 적용해 시각화를 해보면 위 그림과 같다. 점은 학습 데이터이고 색상은 점의 라벨을 나타내는 것으로 이해하면 된다. 그림을 보면 몇 가지 문제를 찾아볼 수 있다. 초록색 영역 사이에 노란 점, 파랑 부분으로 넘어가는 초록, 빨간 점 등이다. 이런 문제 때문에 좀 더 일반화시켜 K-NN을 만들었는데 이는 가장 가까운 이웃만 찾는 것이 아닌 가까운 이웃을 k개 만큼 찾고 다수결의 원칙을 이용해 가장 많은 라벨 값으로 예측하는 방법이다.

K가 1인 경우는 NN과 일치하지만 3이나 5인 경우 좀 더 일반화 된 것을 볼 수 있다. k값이 올라가면서 흰색 부분이 생기는데 이는 이웃이 다수 없는 위치를 의미한다.

L1 거리 말고도 L2 거리를 이용해볼 수 있다. L2 거리는 제곱 합의 제곱근을 거리로 계산하는 방법이다. 그렇다면 L1거리와 L2거리 중 무엇이 더 좋을까? L2거리가 더 좋아보이지만 문제에 따라 다른 문제이다. 개별요소가 중요할 때는 L1거리가 더 좋게 작용할 수도 있기 때문이다. 즉, 직원을 분류하는 문제에서 직원의 급여나 근속년수와 같은 개별적인 의미, 영향을 주는 값들이 있을 때 L1거리가 우세하다.
하이퍼파라미터, 데이터 셋 나누기
모델을 만들기 위해 우리가 선택해야하는 값을 하이퍼파라미터라고 한다. 예를 들어 앞에서 나온 k값이나 거리 계산하는 방법(L1 or L2) 와 같은 것이 해당된다. 다양한 하이퍼 파라미터를 시도하고 그 중 최고를 고르는 튜닝작업을 해야한다.

이 때 조심해야할 것이 위 그림처럼 학습 데이터의 정확도와 성능을 올리겠다고 학습 데이터를 모두 사용해 이를 최대화하는 값을 선택하면 안 된다. 학습데이터가 아닌 새로운 테스트 데이터를 주면 성능이 급락할 수 있기 때문이다. 모델을 만들 때 생각해야할 점이 학습데이터를 잘 맞추는 지에 대한 문제보다 새로운 데이터를 얼마나 잘 예측하느냐가 더 중요하다는 것이다. 물론 학습데이터를 너무 못 맞추는 경우 과소적합의 문제 일 수 있어 이 또한 생각해야할 점이지만 이는 나중에 내용이 나오면 설명하겠다.

아무튼 새로운 데이터를 생각해야하는데 그렇다면 위 사진처럼 데이터 셋을 두 가지로 나누면 될까? 이 역시 문제가 있다. 한 번도 보지 못한 데이터에 대해 좋은 예측을 하길 바라지만, 위 그림은 테스트 데이터에만 잘 작동하는 값, 모델을 고른 것일 수 있기 때문이다.

따라서 데이터를 세 파트로 나눠 진행하는 경우가 많다. 대부분을 학습용 데이터 셋, 다음은 검증용 데이터 셋, 마지막으로 테스트 용 데이터 셋으로 만드는 것이다.
위 과정을 쉽게 설명하면 수능에 비유할 수 있다. 수능 시험문제를 모두 알고 푸는 것이 맨 처음 아이디어, 즉 정답을 다 알고 있는 상태인 것이다. 다음은 모의고사로 연습을 하고 기출문제를 봤는데 잘 나왔다. 하지만, 새로운 수능 시험을 접하면 망하는 경우이다. 따라서 중간에 검증용 모의고사(6, 9 평가원 모의고사)가 필요하게 되는 것이다.
써놓고 보니 비유가 이상하네..
Cross Validation
교차 검증으로 부르는 cross validation은 테스트 데이터를 정해놓고 나머지 데이터를 학습, 검증용으로 나누는 것이다. 이 때, 일반적으로 나누는 두 부분으로 나누는 것이 아닌 여러 부분으로 쪼개는 것이다. 보통 다섯 부분으로 쪼개는 5fold 방식을 택한다. 아래 그림 처럼 5부분으로 나누고 한 파트씩 검증 데이터로 변경해가면서 진행하는 것이다.

Linear Classifier
실제로 K-NN 분류기는 잘 사용하지 않는다. 너무 느리기도 하고 L1, L2거리가 이미지 간의 거리를 계산하기에는 부족한 점이 많기 때문이다. 또한, KNN이 잘 학습하기 위해서는 충분한 학습용 데이터 셋이 필요한데 현실적으로 많은 양의 학습용 데이터 셋을 구축하는 것은 힘들기 때문이다.
Linear Classifier 역시 잘 사용하지는 않지만 강의에서 언급하기 때문에 간단히 설명하고 넘어가겠다. 해당 모델은 입력 이미지를 x로 쓰고 가중치를 W라고 한다. 아래 강의 자료를 참고하면 이해하기 편하다.

자료에서 볼 수 있듯이 32 * 32 * 3에 대한 이미지 값을 x로 받고 가중치 W를 가지며 선형회귀와 마찬가지로 bias인 b를 통해 계산해 10개의 숫자를 출력한다. 출력으로 나온 이 10개의 숫자는 각 라벨(카테고리)에 대한 스코어 값이다. 여기서 고양이 라벨이 가장 높게 나왔다면 해당 이미지가 고양이일 확률이 높다는 것이다.
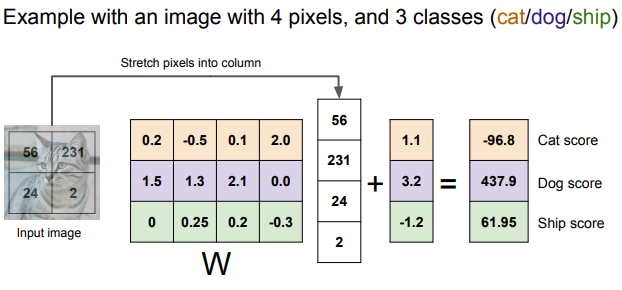
예시로 2 * 2 크기인 이미지를 입력으로 받을 때의 계산과정을 그림으로 나타낸 것이다.
'개인 공부 > CS231n' 카테고리의 다른 글
| CS 231n 정리 시작! (0) | 2022.01.09 |
|---|